Ofertas en: Ingeniería en Organización Industrial
Contacto:
Juan Carlos Ramos (jcramos@tecnun.es)
Duración estimada 300-350 h
Contexto
Bajo la Cátedra de Empresa Tecnun - SAPA se ha estado diseñando un banco de pruebas de engranajes de alta velocidad. Dicho banco requiere ahora una evaluación de los costes de fabricaci´on y montaje que determinen de manera preliminar el gasto de materializar el banco.
Objetivos
Comprender el funcionamiento del banco y la disposición de sus elementos, así como sus características y su proceso de fabricación y montaje. Recoger toda la información del banco necesaria para calcular el valor de cada elemento. Emplear software de análisis de costes para hacer un recuento detallado y una suma total. Proveer los resultados de manera justificada.
Aptitudes
-
Siemens NX Viewer
-
Microsoft Dynamics
-
Microsoft Excel
-
Trabajo en Equipo
-
Comunicación
Descripción y objetivos:
La industria de la madera genera una gran cantidad de materiales sobrantes, tanto madera como componentes que están en buen estado que actualmente no se utilizan o aprovechan adecuadamente.
Este proyecto tiene como objetivo la mejora de la circularidad de la actividad de las empresas asociadas a Arozgi que trabajan con madera, a través de la simbiosis industrial y el desarrollo y puesta en marcha de un catálogo de productos y proyectos en la plataforma Circular Market, desarrollada por Tecnun.
Las fases que se llevarán a cabo para alcanzar el objetivo son las siguientes:
-
Análisis e identificación de recursos generados por las empresas (productos, residuos, componentes, subproductos) pero con potencial valor. Este análisis incluirá tanto los recursos reales como la identificación de las mejores técnicas disponibles para su valorización.
-
Evaluación de estos recursos para facilitar su aprovechamiento, incluyéndolos en un repositorio en CircularMarket.
-
Diseño de la promoción y actuaciones necesarias para dinamizar la utilización de dichos residuos como productos para otras empresas y el fomento de simbiosis entre ellas.
Supervisor académico:
Carmen Jaca
Área temática:
Sostenibilidad y Economía Circular
Área o departamento:
Ingeniería de Organización Industrial.
Supervisor académico:
Itxaro Errandonea
División CEIT:
Análisis de Datos y Gestión de la Información
Área temática:
Inteligencia Artificial
Descripción y objetivos:
Muchos procesos industriales reales se pueden formular matemáticamente mediante modelos mecanicistas complejos compuestos por ecuaciones diferenciales no lineales. Aunque estos modelos son de gran utilidad para llevar a cabo estudios de diseño y operación, su hándicap es su alto coste computacional el cual los hace inviables para su uso en la toma de decisiones en tiempo real.
Con la llegada de las técnicas de Deep Learning, han surgido propuestas que permiten reducir la complejidad de estos modelos y con ello el coste computacional. El cometido de este PFG será utilizar la técnica conocida como “physics informed neural networks” para obtener un modelo reducido de una planta de tratamiento de agua. Para llevar a cabo el proyecto se utilizará el entorno Python.
-
El proyecto Codex es una plataforma online para la investigación en nuevas metodologías para mejorar el proceso de aprendizaje a través de aumentar la interacción entre enseñantes, aprendices y el material.
En este proyecto se analizará, diseñará e implementarán las funcionalidades necesarias para que en Codex se puedan definir plugins. Los plugins permitirán incorporar nuevas funcionalidades sin necesidad de cambiar el código base, mediante la definición de funciones en JavaScript que el usuario del plugin configura en la aplicación. En el proyecto se desarrollarían las funcionalidades para su soporte y algún plugin de ejemplo.
Ejemplos de plugins que se podrían definir en el proyecto son: modificación del interfaz de los test en función del tipo de pregunta, definición de plantillas con interfaz específico para determinados tipos de pregunta, generación de gráficos en base a los datos proporcionados por la aplicación, interacción con la aplicación desde clientes distintos como puede ser una aplicación de MS Office, etc.
El proyecto Codex es una plataforma online para la investigación en nuevas metodologías para mejorar el proceso de aprendizaje a través de aumentar la interacción entre enseñantes, aprendices y el material.
En este proyecto se analizará, diseñará e implementarán las actividades necesarias para la aplicación de la plataforma Codex en uno de los siguientes temas:
-
sistemas de información (bases de datos y diseño Web)
-
pre cálculo (geometría, trigonometría)
-
programación con Python
El material consistirá en breves explicaciones, ejercicios, problemas, videos, animaciones y scripts de algunos de los ejercicios.
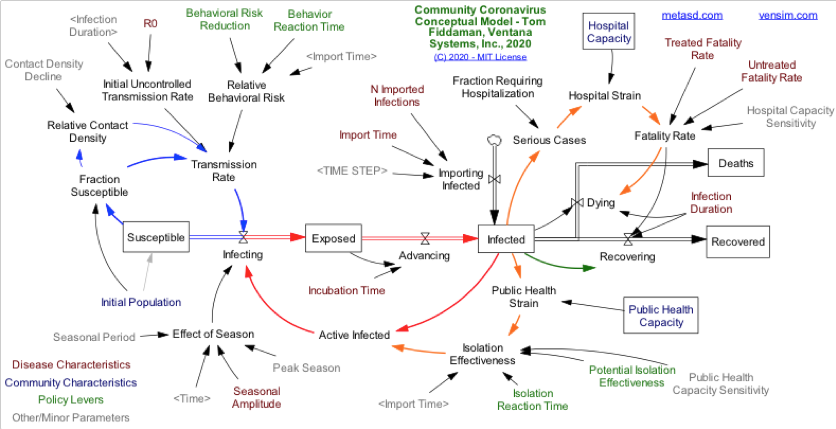
Scope: System Dynamics Model applied to the prediction of Coronavirus spread and its consequences
Goal: Develop a SD Model to predict the evolution of a Pandemic based on some key parameters.
How: ting from an existing model, add new loops, stocks and flows to cover other influences associated with the pandemic evolution. Both the old and the new models should be represented using Vensim.
Approach: Test the model against real data obtained from past reports and use the results to tune the new model. The data used will be that available for the Basque Country (EUSKADI).
Requirements: Knowledge about SD modeling; knowledge about VENSIM, access to Data
Deliverables:
- The SD model in VENSIM;
- A set of graphs generated by the simulation;
- The description of parameters settings and the contents of the reports;
- The comparison between the results generated by the model and the real information obtained by the reports;
Tools to be mastered: VENSIM; VENTITY
Development time: between 2 and 3 months with 20 hours per week dedication
Sources: Initial Vensim Model (https://vensim.com/coronavirus/)
Data for Euskadi covid19: Evolución del coronavirus en Euskadi
General on Epidemics SD modeling: Several articles available on demand
Scope: There has been a lot of recent publications on Pandemics due to the outbreak of covid-19. There is also a high demand of projects for analyzing the evolution of pandemics particularly for new waves of other types of Pandemics.
Goal: The goal of this project is to generate a data base of literature, both scientific and informative (newspaper and web). As a side product, another goal is to generate a taxonomy to facilitate understanding and clustering.
How: Perform a systematic review of the literature and save the relevant results in Mendeley. At the same time perform a literature search using an automatic tool generating another set of results. Compare and unify the results and, most importantly, the taxonomy.
Approach: Design a search query for the retrieval of elements, using google on one side and scientific bases on the other. For the google query, the relevant results should be stored in the Mendeley Digital Library, adding additional metadata, in particular, the taxonomy classification. In parallel, a similar search should be performed using Bibliometrics tool to select, classify the elements extracted from Web of Science and Scopus bases. Finally, the results of both searches should be confronted and combined, generating a single DL and a unique taxonomy.
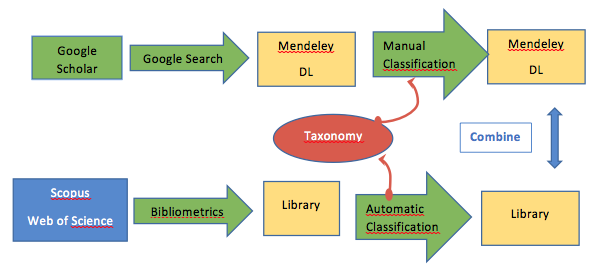
Requirements:
- Knowledge about Dl and particularly Mendeley;
- knowledge on Bibliometrics tool;
- knowledge in Taxonomies.
Deliverables: A systematic review of the literature describing the search and selection mechanisms, with corresponding taxonomy and the DL.
Tools to be mastered: Mendeley and Bibliometrics
Development time: Estimated between 2 and 3 months
Sources:
- An initial Mendeley DL
- An initial taxonomy